Distributed Data Structures in R for General, Large-Scale Computing
Michael J. Kane
Phronesis, LLC and Yale University
Acknowledgements
Simon Urbanek and AT&T Research Labs
A portion of this research is based on research sponsored by DARPA under award FA8750-12-2- 0324. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon.
Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of DARPA or the U.S. Government.
Deconstructing Distributed Computing
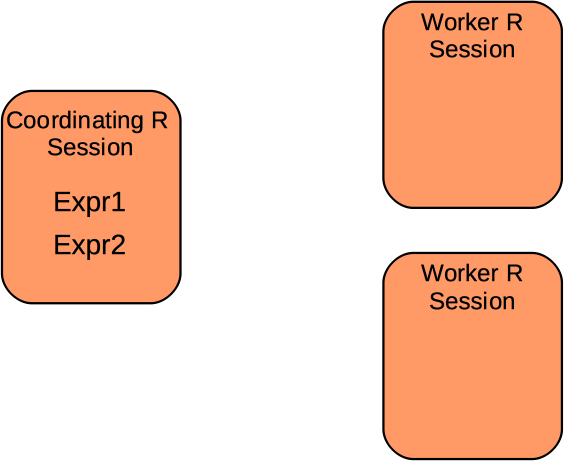
Deconstructing Distributed Computing
- move expression to a parallel process
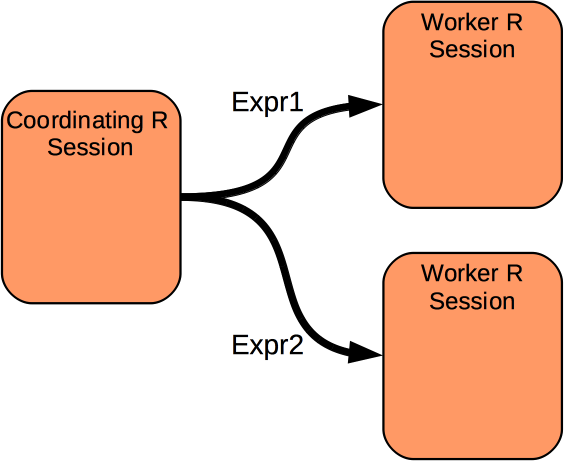
Deconstructing Distributed Computing
- move expression to a parallel process
- evaluate the expression
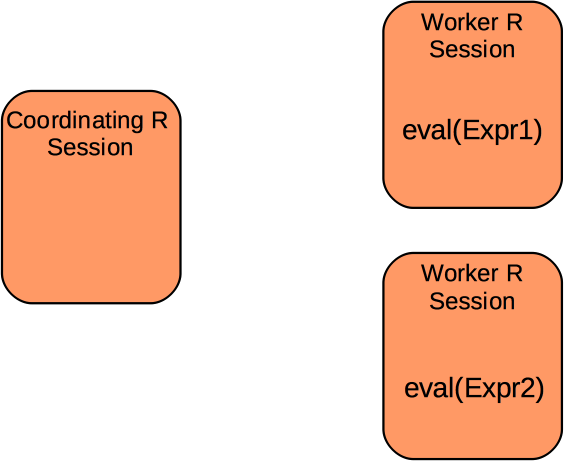
Deconstructing Distributed Computing
- move expression to a parallel process
- evaluate the expression
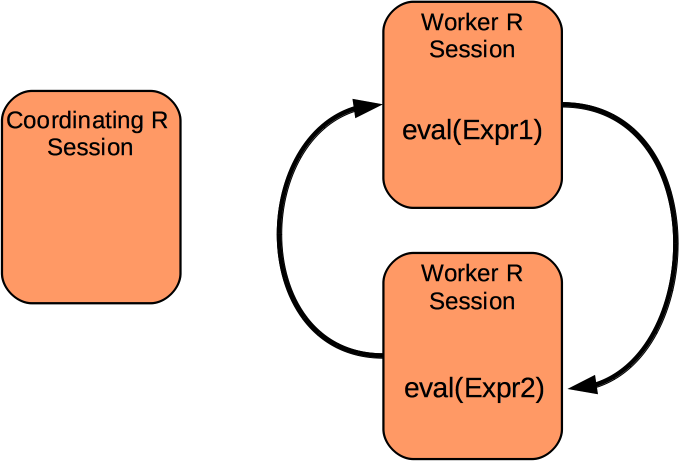
Deconstructing Distributed Computing
- move expression to a parallel process
- evaluate the expression
- return the result
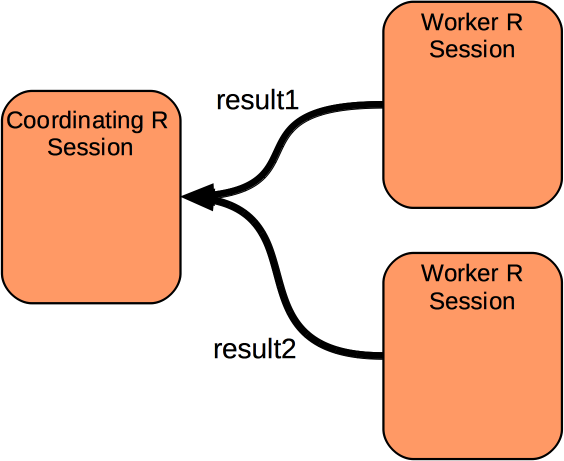
What do we need to facilitate this?
- coordinator to describe the computation
- worker to evaluate the expression
- mechanism for getting data from the coordinator to the worker
- possibly a mechanism for moving data between workers
- mechanism for getting results to coordinator
Creating a distributed computing is about defining a communication protocol
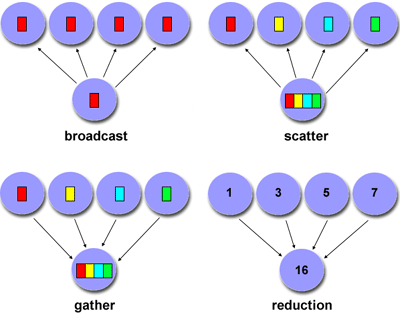
MPI
- data movement for a computation is defined up-front
- workers (slaves) communicate directly through "mailboxes"
- performance is excellent
- not very fault-tolerant
Configuration service
R coordinator session
> library(rredis)
> redisConnect()
> redisLPush("worker_queue", "hello worker session")
[1] 1
> redisBLPop("coordinator_queue")
$coordinator_queue
[1] "hello coordinator session" R worker session
> library(rredis)
> redisConnect()
> redisBRPop("worker_queue")
$worker_queue
[1] "hello worker session"
> redisLPush("coordinator_queue", "hello coordinator session")
[1] 1 Redis
- workers block on queues (Redis lists)
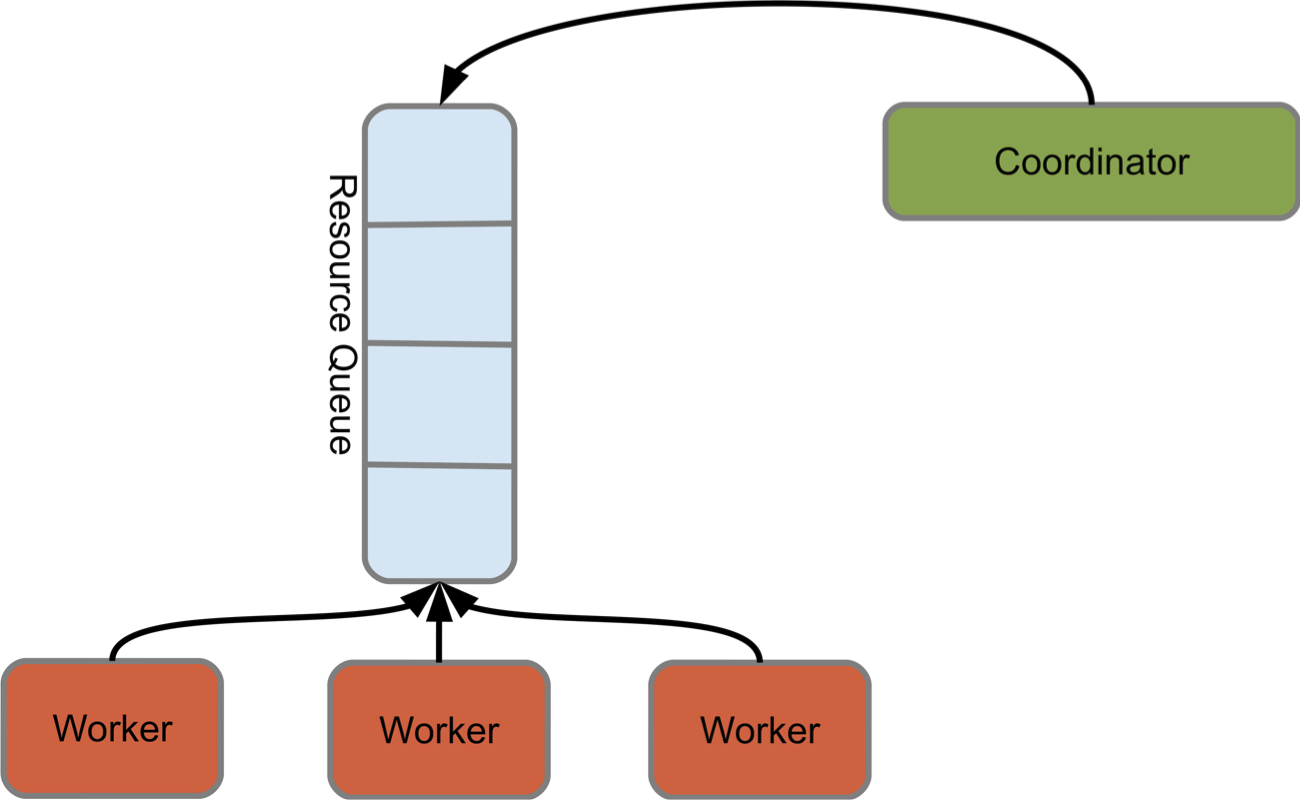
Redis
- workers block on queues (Redis lists)
- workers return evaluated expressions on a result queue
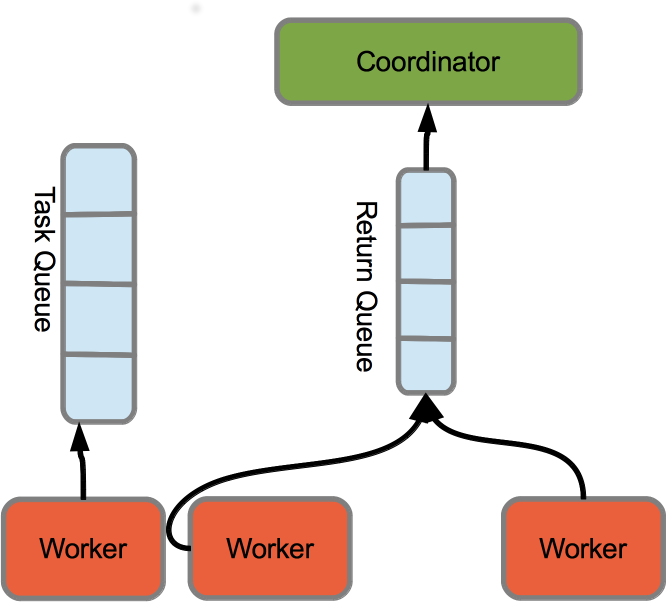
Redis
- workers block on queues (Redis lists)
- workers return evaluated expressions on a result queue
- buys us communication orthogonality
Redis
- workers block on queues (Redis lists)
- workers return evaluated expressions on a result queue
- buys us communication orthogonality
- trade off is centralization of data movement
Build a communication framework that:
- Allows you to put computations into a cluster to be consumed
- Can return the result of a computation or a handle to the result
- Is elastic
- Does not require that data moves through a centralized, configuration manager
- Simple and lightweight
cnidaria
A phylum of simple marine animals that are regenerative
How does it work?

How does it work?
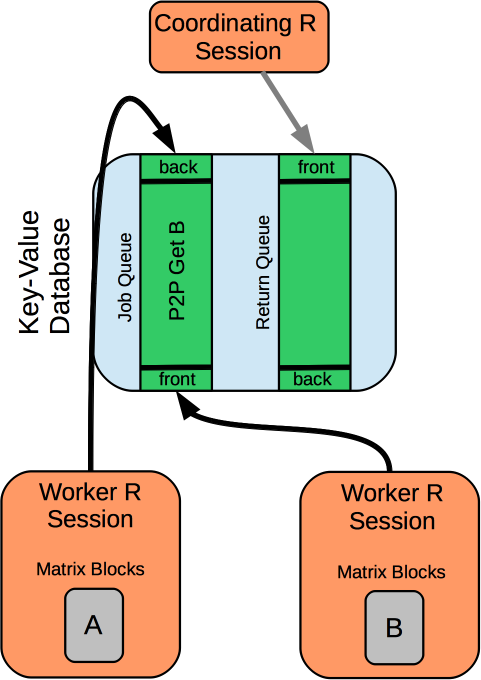
How does it work?
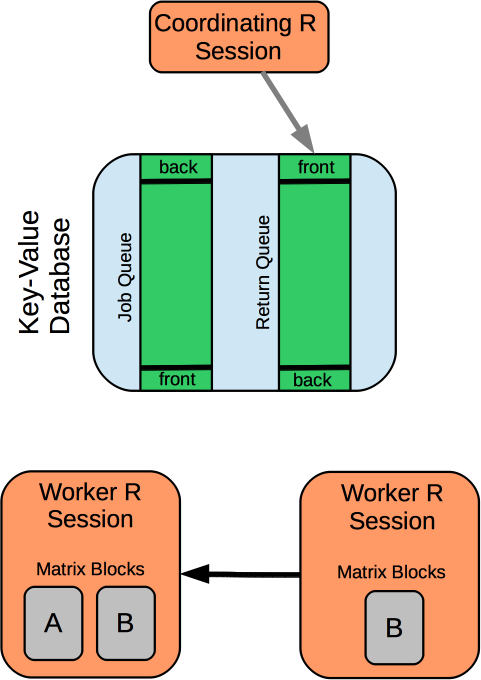
How does it work?
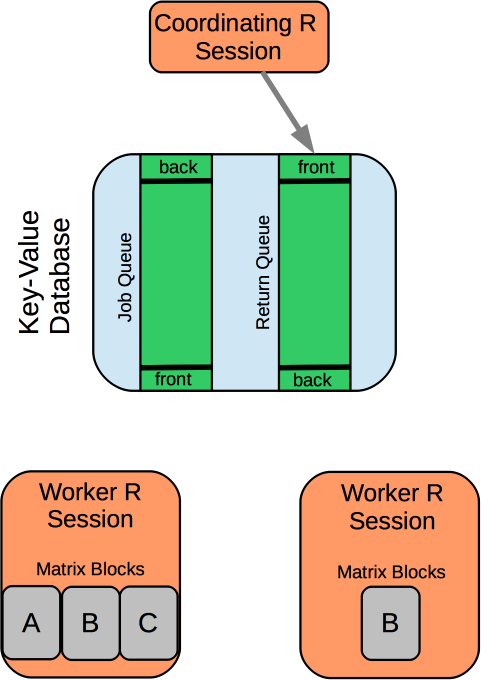
How does it work?
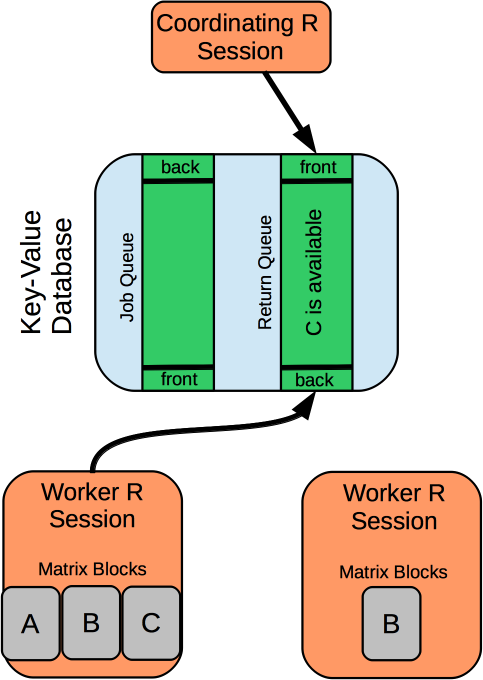
How is it used?
- pull( <resource location>, <expression>, broadcast=FALSE ) - executes an expression at a resource location and returns the result
- push( <resource location>, <expression>, resource_name=guid(), broadcast=FALSE) - executes an expression at a resource location and returns the name of a new resource
push( "A", "B %*% pull('B', 'B')", "C" )
A Generative Communication Framework (cf Gelernter 1985)
- space uncoupling (distributed naming)
- time uncoupling
- distributed sharing
- support for continuation
Bottom line is that you can support a large class of distributed communication patterns.
Space Uncoupling (distributed naming)
A resource identifier can be used by any member of the cluster
push( "B", "B %*% pull('A', 'A')", "C" )
# "C" is now available to any member of the
# cluster
push( "D", "pull('C', 'C')", "C")
Time uncoupling
A resource is available to the cluster until it is explicitly removed
pull( "C", "rm(C)", broadcast=TRUE )Distributed sharing
Data can be shared across R sessions
- Resources can be stored redundantly
- Provides multi-map capabilities
-
Consistency implemented as a policy
Continuation passing
Expression arguments to pull and push can themselves call pull and push
How do we handle deadlocks?
Handling deadlocks with new R functionality
pull("A","pull('B','pull(\"A\", \"A\")')")
The new mcparallel functionality
> ?mcparallel
mcparallel(expr, name, mc.set.seed = TRUE, silent = FALSE,
mc.affinity = NULL, mc.interactive = FALSE,
detached = FALSE)
detached: logical, if ‘TRUE’ then the job is detached from
the current session and cannot deliver any results back - it
is used for the code side-effect only.
The background package
require(background)future = function(expr) { p = parallel::mcparallel(expr) async.add(p$fd[1], function(h, p) { async.rm(h) print(parallel::mccollect(p)[[1]]) }, p) invisible(p) } future({Sys.sleep(5); "done!" }) # in 5 seconds you'll see the output
Conventions for distributed data structures (DDS's)
- A DDS should look and feel like analogous local data structures
- An operation involving a DDS should return a DDS by default
- A DDS with dimension attributes can be "emerged" on a local machine with "[]"
-
You should be able to stream values held by a DDS with an iterator
dist.vector
dv <- distribute.vector(rnorm(1000), 79)
iv <- distribute.vector(sample(1:length(dv), 35, replace=TRUE), 14)
a <- dv[iv]
expect_that(dv[][iv[]], equals(a[])) - implemented in vector blocks
-
index with vectors or distributed vectors
- currently working on binary infix operators
dist.data.frame
tickerInfo <- getReturns("DORM")$full[["DORM"]]
ddf <- distribute.data.frame(tickerInfo, 83)
expect_that(ddf[], equals(tickerInfo)) it <- ibdf(ddf, chunkSize=47)
isi <- isplitIndices(nrow(tickerInfo), chunkSize=47)
expect_that(nextElem(it), equals(tickerInfo[nextElem(isi),]))
- implemented in row blocks
- indexed with vectors, distributed vectors
dist.matrix
- Still in early development
- Underlying representation is a matrix of resource handles
- Will support matrix multiplies
-
Will support sparse, dense, and mixed matrices
> a <- matrix(letters[1:4], nrow=2)
> a
[,1] [,2]
[1,] "a" "c"
[2,] "b" "d"
>
> char_prod(a, a)
[,1] [,2]
result.1 "a %*% a + c %*% b" "a %*% c + c %*% d"
result.2 "b %*% a + d %*% b" "b %*% c + d %*% d"
Future directions
Streaming data worker topologies
Scheduler
Further Information:
In R type:
?parallel:::mcparallel
-
Simon's background http://www.rforge.net/background/.
- The cnidaria package https://github.com/kaneplusplus/cnidaria.
-
NIPS 2013 paper http://biglearn.org/index.php/Papers.
-
Email me with questions at michael dot kane at yale dot edu.
?parallel:::mcparallel
- Simon's background http://www.rforge.net/background/.
- The cnidaria package https://github.com/kaneplusplus/cnidaria.
- NIPS 2013 paper http://biglearn.org/index.php/Papers.
-
Email me with questions at michael dot kane at yale dot edu.
Distributed Data Structures in R for General, Large-Scale Computing
By Michael Kane



